




集成预报
集成预报是进行具有随机特性的天气预报工具。对日益不可或缺的确定性天气预报而言,集成预报既是另一选择,也是一种补充。集成预报通过随机描绘数值天气预报中的误差来模拟其最可能的演变。这些不可避免的误差可能来自大气的初始状态,方程的近似,或陆气、海气界面建模时普遍接受的不确定性。
1. 集成预报的意义和原理
人们可基于观测使用模型(例如,数值天气预报模型,NWP)(参见天气预报介绍)来模拟一个真实的系统的演变(这里指的是大气)。由此可产生对未来天气可能的最佳估计,即确定性预报。随后便利用最佳数据来进行一次预报。众所周知,在实践中由于缺少初始数据、观测有误差,以及在数值模拟过程中所做的近似,这种预报往往是不准确的。此外,由于大气的混沌特性,天气预报的误差会放大,这就是蝴蝶效应,即:数据或模型中的一个微小误差会在几小时或几天后使预报完全偏离。其实,天气预报必须要比常规方法更好,更便宜才是实用的,比如可直接用季节均值进行天气预报。通常,我们将可以做出有用预报的时间尺度称为可预报水平。目前阵雨天气的平均值是几分钟,暴风雨是几小时,低压或气旋是几天,寒潮或热浪是几周,厄尔尼诺等热带气候异常则为几个月。
这个预报水平,或预报质量是随时空变化的。因此,我们需要准确知道人们对预报的各个方面的置信度:这时会产生一系列可能的结果,这就是概率预报的目标。由于计算所有可能的备选方案会非常昂贵,因此,解决这个问题的近似方法是用一些经随机扰动的数值预报来代替确定性预报的计算,这就是集成预报。集成预报与确定性预报同样是实时的。如果我们有 n 个预报(称为成员),它们对给定气象参数 x 的所有预报(例如,给定时间和地点的风速)由 n 个值组成,考虑到运行预报时可用的数据,这些值在数学上构成了一个离散样本x的概率密度[1]。本文第3节中提到,集成预报不仅产生参数概率,而且还产生在物理上清晰的全方位时空天气图像。因此,它是一个非常丰富的信息资源,如何正确使用这些信息本身就是一种挑战。
洛伦兹普及了气象学中可预报水平的概念[2],他对蝴蝶效应图像相关的混沌过程的阐释给公众留下了深刻的印象。托特和卡内尔[3]使用美国气象模型进行了首次实时业务集成预报。从那时起,集成预报技术无论是预报本身,还是在数据同化方面都得到了完善,并应用于所有主要的气象服务中(洛伊特贝歇尔和帕尔默[4])。同时,它也被推广到诸如:工业、金融、水文等部门的季节预报中[5](见季节预测)。
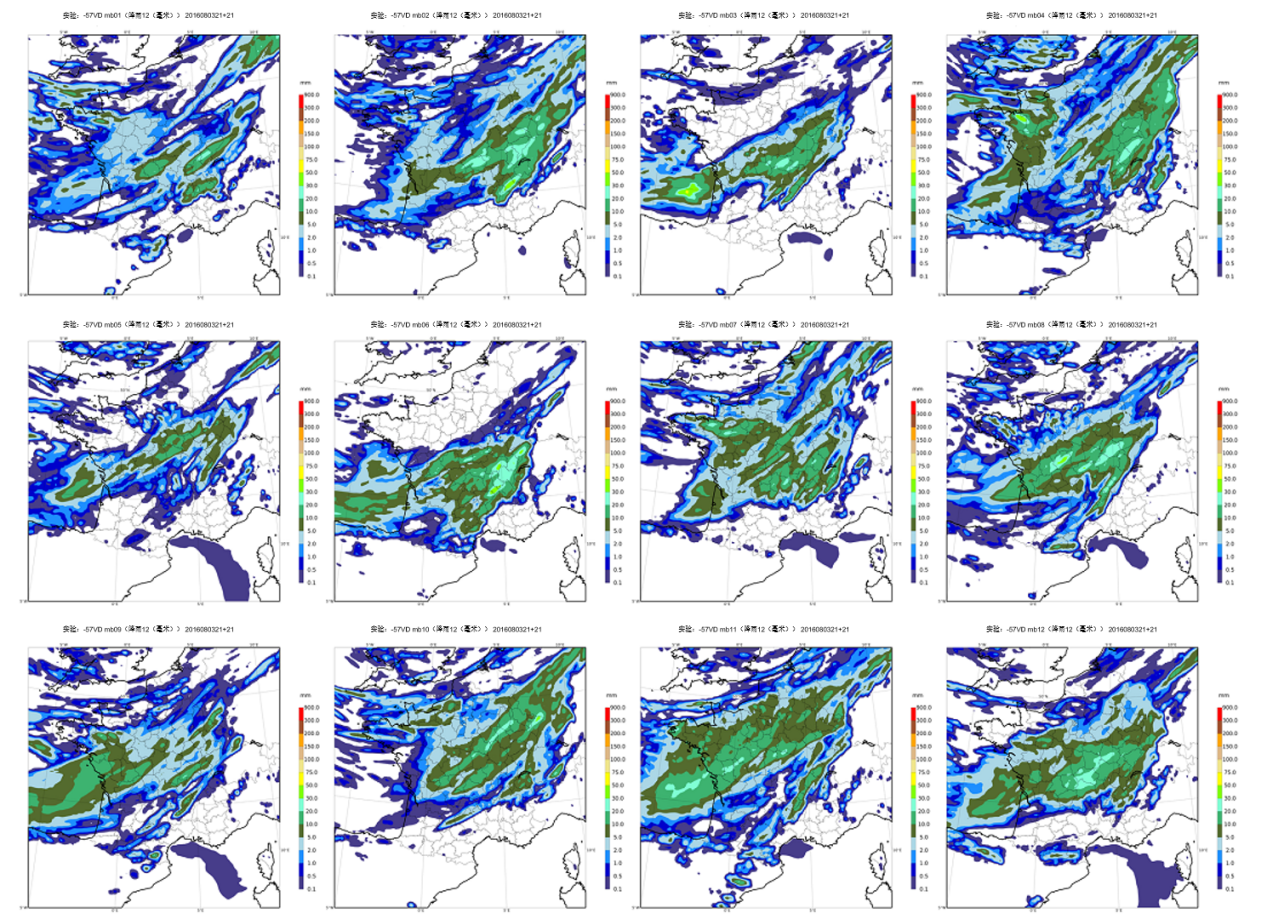
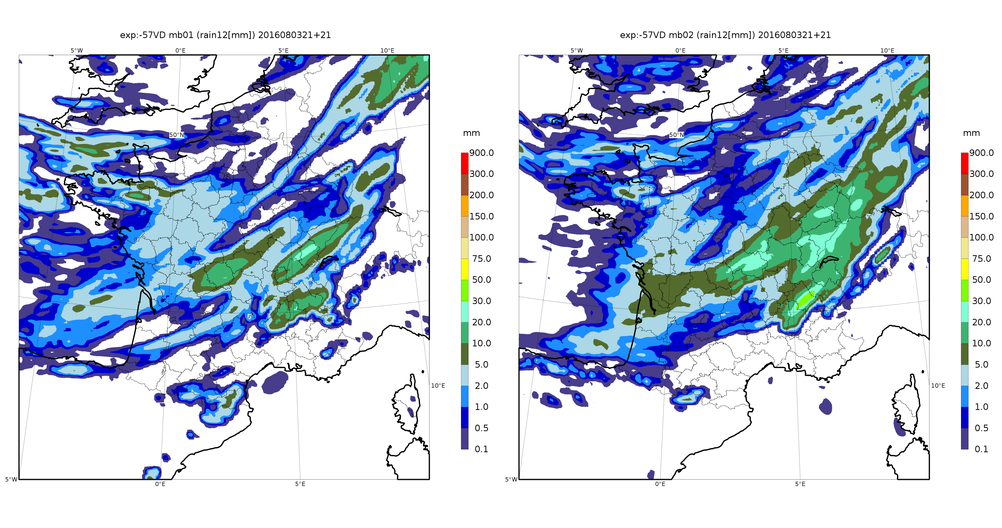
从业务预报的角度来看,进行全面预报时,需要通过随机扰动其输入数据和软件计算本身来执行一个数值预报软件n次。这些扰动应该合理地反映所有这些数据(例如观测误差)和计算的不确定性(已知建模不佳的气象过程,例如海洋表面流动)的分布,从而使我们能模拟模型中所有误差的可能演变及其对预报结果的影响。受较大误差或混沌放大扰动影响的参数,将比在受扰动后预报保持稳定的参数的结果更分散:由此,集成预报的离散度为我们提供了数值模型模拟天气现象可预报性的信息(图 1)。
2. 天气预报会如何受到扰动?
在实践中,由于我们对误差来源的认识非常有限,只有数值预报系统的一些关键方面受到扰动。目前而言,扰动主要涉及如下方面:
- 预报的初始状态。其目的是表征分析过程中主要与观测误差和数据同化算法的缺陷有关的不确定性。最简单的方法是在确定性分析中加入数值噪声[6],例如高斯噪声,其空间相关性和振幅应与过去的统计分析一致。这种噪声也可以由最近的分析或预报之间的差异的线性组合来构建(LAF 方法:滞后平均预报)。一种常见的方法是在分析中添加优化的扰动,从而使扰动在集成预报时尽快放大,以保证整个过程能模拟当天主要来自混沌的影响。另一种更严格同时也更昂贵的方法是计算整个同化过程的数据集合(参见气象资料同化):这就是集成同化方法,或集成卡尔曼滤波方法。
- 预报模型的方程。这是有关建模错误的问题。可通过将若干版本的大气数值模型混合到集成预报中来(多模型法),或通过改变某些最佳值不明的关键参数(多参数法),或通过向已知的可疑代码的某些部分注入随机扰动(随机物理法)来实现。困难在于,按定义多数建模错误是未知的,因为它们可能来自于未知的气象过程,从而缺乏模拟它们的信息。目前已经专门研究了一些误差来源,例如:由于数值模型分辨率有限,因此不能分辨现实世界中的物理尺度。这个问题可以在集成预报中使用虚拟能源进行模拟(随机能量反向散射法)。
- 界面条件。大气和陆面之间的相互作用是预报误差的一个重要来源。这通常是由于在天气预报中,我们不清楚如何正确表表征物理参数的变化,因而使用人为确定值来表示。因此,有必要以一种特定的方式来表示它们的不确定性,扰动的方式需要与我们对其不确定性的了解相一致。其中,最重要的是土壤、植被、冰雪、海洋的特性,这些特性决定了热流、湿度和湍流的计算。在最精细的集成预报中,界面本身就是一个完整的数值模型,从而可对与大气耦合的系统进行预报。在季节预报时尤为如此。
- 大尺度的耦合。这只适用于具有有限域的数值模型。他们的预报对与之耦合的全球天气模型中的误差很敏感,而这对于预报快速传播的大规模大气波动的演变至关重要。有限区域集成预报必须与真实反映大规模大气演变不确定性的全球集成预报相结合。
3. 从集成预报到应用
集成预报会产生丰富且往往难以理解的信息。从数学的观点来看,集成预报产生了不同大气演变的可能情景。由于大气状态演变的空间维度(数十亿自由度)远大于集成预报(几十个成员),后者只提供了可能演变的概貌。集成预报的解读方法很多,主要有以下几种:
- 训练有素的预报员可通过主观分析集成预报数据(参见预报员的作用)来估计不同预报情景发生的可能性。一般来说,在用户要求解释预报时,预报员会查看由所有近期模型输出(集成或确定性)组成的超级集成。现代预报员可以获得大量来自不同的天气中心、不同的模型或在不同的时间计算的可能性较高的情景,预报员总是以概率推定的方式进行或者命名实际的集成预报。大多数预报员宁愿使用多数模型和成员支持的共识情景;过于非典型的预报通常不被采纳,因为不太可能在公告中提及。然而,如果某些预报表明有发生风险事件的可能,那么该预报则有助于在必要时发出预警。考虑到事件的潜在严重性,可以冒着误报的风险予以发布。在估计天气事件的强度、时间和地点的不确定性时可使用集成预报。所以,集成预报比仅使用确定性预报更可靠,但这也需要预报员付出更多的努力[7]。
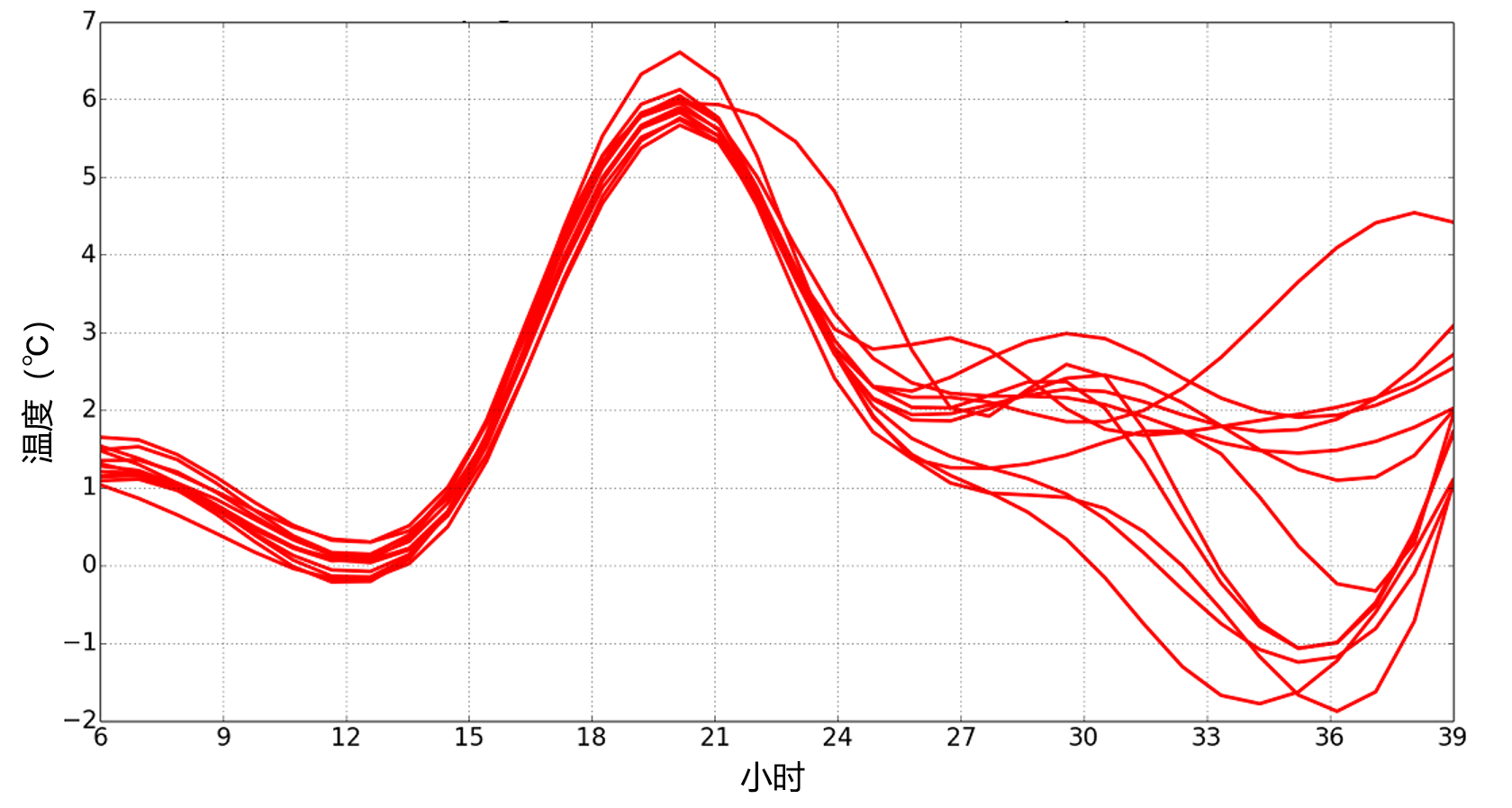
- 出于与上述相同的原因,基于集成的自动预报比仅基于确定性预报的自动预报更有效(即更准确)。事实上,这些集成提供了丰富的信息,使得我们可以综合处理预报。此类处理通常模仿人类在预报方面的专业工作。例如,模型中气象参数在网格点上的预报值分布是该参数的概率分布;在每个点上的数值与成员总数一样多(见图2)。这些值可以通过统计处理来进行修正,以弥补数值模型中的系统缺陷,如:预报值中的偏差,或预报中的置信度过高(与最近的预报中发现的误差相比,该集成的离散度太小)。可以向用户提供的集成预报通常是最可能的中值。然而,如果我们可以为他们提供集成计算的概率分布,效果会更好。比如,即使用户收到的风暴误报数是漏报数的三倍,如果他得到了集成概率大于25%风暴的预警,他实际感觉的误报率会比中值预报或确定性预报要低得多(不管是有意还是无意,大部分普通公众的感受都是如此)。在要求误报率远低于50%的应用场景中,全面的预报对天气预报的改进程度最大。这种预报方法类似于在有经济风险时金融家为使经济损失最小化所进行的计算。由于数值预报处理适用于不同的用户,集成预报便可将此方法应用于具体的天气问题。
- 整体预报的耦合。用天气变量的概率来概括集成预报的情景,往往会导致信息的丢失;在某些应用中,最好将预期成员的数值输出直接耦合到该应用程序特定的复杂计算中。对气象变量空间分布敏感的应用尤其如此:洪水预报与流域尺度的综合降雨分布相关,商用飞机航线与每架飞机通过该航线的时间有关,电网管理又与风能和光伏发电以及家庭供暖情况有关。在这些情况下,由应用模型管理者将天气集成预报转换为自己关心的参数的集成预报,那么这种预报可能会受非气象因素的影响。该工作方法主要针对专业用户,他们本身必须是使用数值天气预报和概率计算方面的专家。
4. 集成预报的价值
如果天气预报说有50%的降雨概率,但实际上并没有下雨,那么该预报是好是坏?我们无法通过一个孤例回答这个问题:概率预报本质上没有好坏之分。为了评估其质量,有必要对预报历史进行统计,这可能会给偶发现象的研究带来一些问题。如上所述,集成预报的使用取决于用户,特别是用户对误报的容忍度。以前一节的例子为例,关注概率25%风暴的用户(如野餐活动组织方)与追寻80%风暴概率的用户(如龙卷风“猎户”)对预报系统性能的认识会完全不同。这两个因素(需要长时间的统计数据和用户的多样性)说明了为什么集成预报的质量需要用相当复杂的数学工具进行衡量。通过简化,我们可以从与集成预报中提炼出度量质量的3个主要指标:
- 可靠性:指针对有后续观测的预报,其预报概率与观察数据统计之间的一致性。可靠性的基本度量——离散度与误差间的关系是(a)集成离散度变化和(b)预报误差幅度变化之间的相关性:在一个可靠的系统中,最分散的预报往往是最差的,所以这种相关性愈高愈好。我们还可以观察以下,当预报给定某概率值时,观测到的预报误差是否与该概率一致。例如:在预报降雨概率为50%的一系列案例中,能否在50%的案例中观察到降雨。测量可靠性可以帮助我们发现整个预报系统的缺陷。然而,这并不能保证所预报结果可用。可靠性测量也无法得出从一种情景到另一中情景时预报的变化程度有多大,而我们恰恰需要这一数据来在不同情景下传达信息。
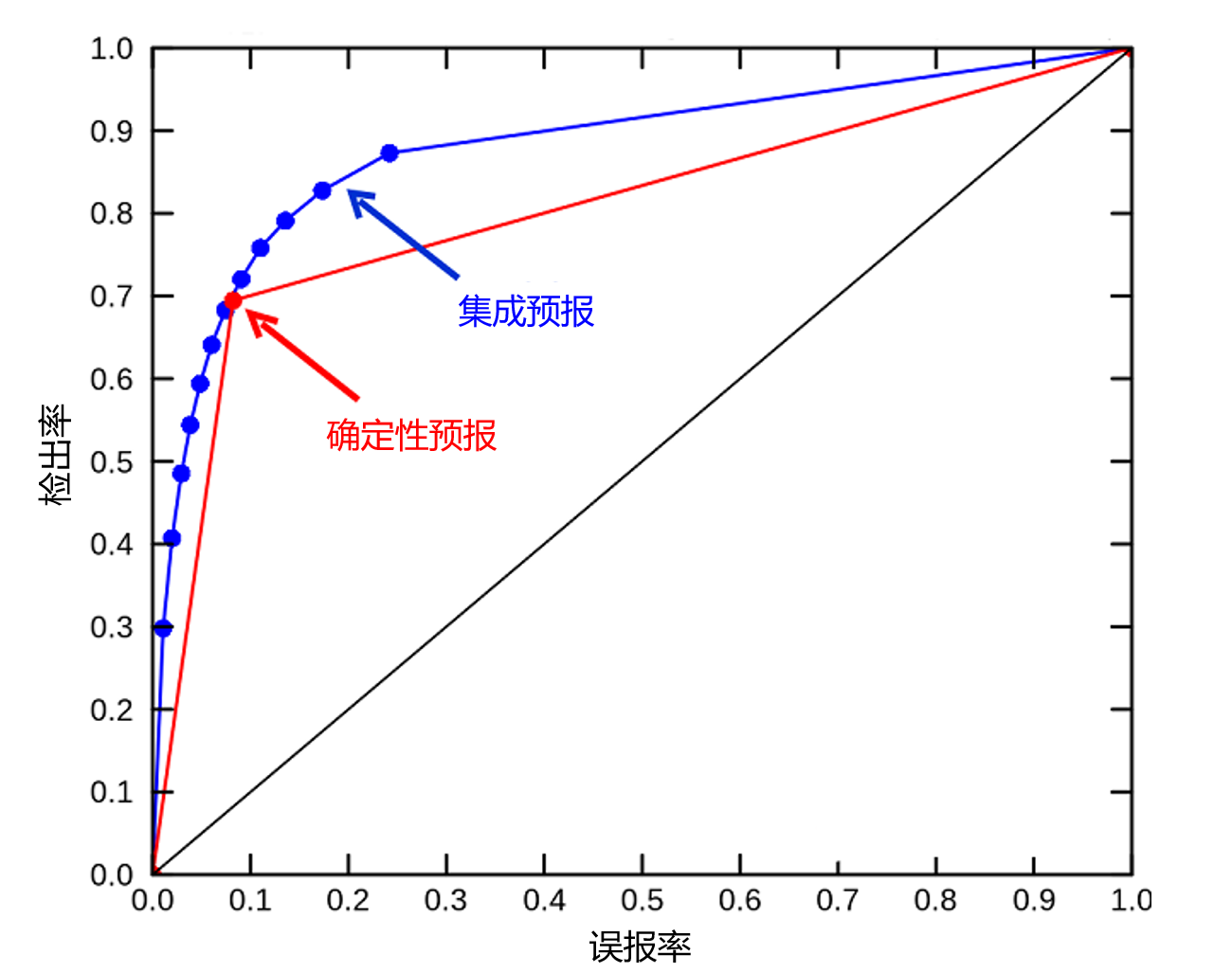
- 统计分辨率,也称为锐度或分辨率,是一种诊断类型,它衡量的是预报概率与气候学有多大差异(即集成是否有“冒险”),它们的平均精度是多少。最常用的工具是ROC图(相对业务预报特性),它衡量所有预期概率水平的预报成功率(即,取大量用户预期成功率的平均值)。ROC对于评估集成预报系统(参见预报员的作用)的内在特性非常有用(见图3)。
- 决策价值(由于历史原因也称为经济价值)衡量的是预报系统对特定类型用户的价值,他们的天气敏感性通常借助两个变量进行参数化建模:(a)对他们来说较为敏感的天气参数的阈值,(b)他们为超出上述阈值的误报和漏报而付出的相对成本。在这个框架下,集成预报的价值,特别是它们对确定性预报[8]的贡献可以被十分严格地量化。使用这种方法需要专门与用户进行交流,以正确地模拟他们对天气的敏感性。
任何预报系统都必须克服的第四个障碍是用户对信息的理解。虽然目前的集成预报远非完美,但它们在很多用途中都具有极高的决策价值。遗憾的是,它们经常被用户方误解,用户往往愿意使用不成熟但易于理解的预报工具。集成预报目前面临的最大挑战是如何实现集成所产生的信息的自动化处理,从而使集成预报成为一种既智能又精确的预报工具。
参考资料及说明
封面图片:2016年8月4日法国的降雨预报。
[1] 概率密度是一个函数,它在数学上描述了一个参数可能取值的范围。
[2] Lorentz, E. N. 1963: Deterministic nonperiodic flow. Journal of Atmospheric Sciences. 20 : 130-141.
[3] Toth, Z., and E. Kalnay, 1993: Ensemble forecasting at NMC: The generation of perturbations. Bull. Bitter. Meteor. Soc., 74, 2317-2330.
[4] Leutbecher, M., and T. N. Palmer, 2008: Ensemble forecasting. J. Comp. Phys. , 227, 3515-3539.
[5] Hagedorn, R., F. J. Doblas-Reyes, and T. N. Palmer, 2005: The rationale behind the success of multi-model ensembles in seasonal forecasting–I. Basic concept. Tellus, 57A, 219-233.
[6] 噪声的相关性衡量其在某一点的值与其在相邻点的值之间的关系。
[7] Novak, David R., David R. Bright, Michael J. Brennan, 2008: Operational Forecaster Uncertainty Needs and Future Roles. Wea. Forecasting, 23, 1069-1084. doi: http://dx.doi.org/10.1175/2008WAF2222142.1
[8] 气候学是指过去观察到的天气情况的统计分布。
环境百科全书由环境和能源百科全书协会出版 (www.a3e.fr),该协会与格勒诺布尔阿尔卑斯大学和格勒诺布尔INP有合同关系,并由法国科学院赞助。
引用这篇文章: BOUTTIER François (2024年3月12日), 集成预报, 环境百科全书,咨询于 2026年7月22日 [在线ISSN 2555-0950]网址: https://www.encyclopedie-environnement.org/zh/air-zh/overall-forecast/.
环境百科全书中的文章是根据知识共享BY-NC-SA许可条款提供的,该许可授权复制的条件是:引用来源,不作商业使用,共享相同的初始条件,并且在每次重复使用或分发时复制知识共享BY-NC-SA许可声明。

